Our spark application is going to be a mixture of actions and transformation. Jobs, stages and tasks are interdependent entities that are result of the execution of our program
Jobs:
Based on the number of actions that we specify the Driver converts our program to one or more Jobs. Each Job will consist of one or more Stages.
Stages:
Stages are created based on what operations can be performed serially or parallelly. Stages are a group of tasks. Spark tries to group as many tasks as possible. Each stage can have a dependency on another stage. The Stages and their dependencies are represented as Directed-Acyclic-Graphs (DAGs).

Stages are separated when there is need for shuffling (which will be covered in another article) to perform the next transformation. So we can say the number of stages in a job depends directly on the number of shuffle operations that need to take place. What does this mean in the context of the above diagram is that between the every two stages shuffling happens. The arrow that separates is not just to connect the stages but also representation that shuffling is taking place.
When there are dependencies between stages, it means that they have to be sequentially executed. Stages can also not have dependencies, in that case the stages are executed parallelly.
Tasks:
As mentioned earlier, each stage in Spark consists of tasks. Task is the smallest unit of work in Spark. Each task works on a single partition on one of the Executor’s cores. As mentioned in one of the previous articles, multiple partitions can be assigned to a single core. So if there are 500 partitions, we will have 500 tasks that can be executed in parallel.
Pipelining:
Pipelining is one of the optimizations that Spark does. As mentioned above Spark tries to group as many as tasks within a Stage, which do not need shuffle to happen(Narrow Transformations). This grouping is possible when there is no need for shuffling between operations. So for example, let’s say I have the following table:
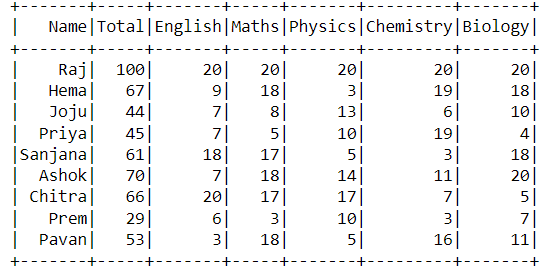
Conclusion:
This article should have given you the basic idea about jobs, stages, tasks and pipelining. If you have any suggestions or questions please post it in the comment box. This article, very much like every article in this blog, will be updated based on comments and as I find better ways of explaining things. So kindly bookmark this page and checkout whenever you need some
reference.
Happy Learning! 😀
Comments
Post a Comment