As mentioned in one of the previous articles, all the Major APIs provided a way to store distributed immutable collection of data.Since the data structures provided are immutable, how do we go about modifying the existing data? It is true that we can instruct spark on what modifications are to be done on the distributed data and these instructions are called Transformations.
Transformation:
Transformations are instructions specifying on what modifications are to be done on the data. Since the
collections provided are immutable, no transformation is done in place.That is every set of transformations
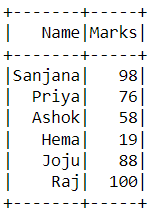
results in a new collection. To show an example, let us take a table with the following schema:
Since I want the data to be structured and take advantage of the optimizations Spark provides,
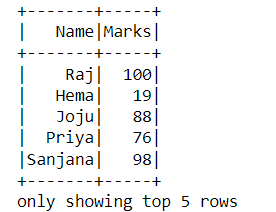
The focus of this example is just to demonstrate the working of Transformation. So let’s say we want only the students with marks less than 50, the transformation could be expressed something like the following using DataFrame API:
This command does exactly what we want, it basically filters out records where the value in Marks column is less than 50, but the point to note here is this command will not return any results. What it returns is another data frame:
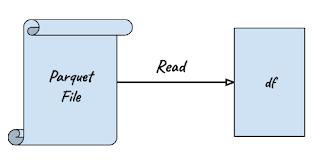
This behavior is due to a characteristic of Transformations. Transformations are lazily evaluated. Spark just registers that in order to generate data for df1, it needs to perform a where clause on the df. Then you might be wondering about df and how it came to picture, I read it from a parquet file and if I try to print out df, I would get a similar output:
For every collection, Spark tracks the operations that are to be performed in order to generate data for that collection. The tracked operations form a lineage. Lineage of df, can be pictured like the following:
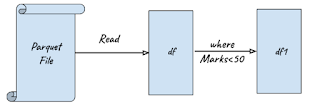
Based on the lineage of df we can picture the lineage of df1:
There are operations that can actually make Spark generate the results for our collections which
we will cover in a short while. But until those operations are called all you have in your
DataFrame object is metadata of what operations are to be performed in order to generate data.
Lazy Evaluation:
Lazy evaluation means that the computation is not done immediately after we run a command.
To give you a better idea, let's say I want to prepare a dish,ex: Egg fried rice. The recipe can be compared to the lineage, cooking your rice is one of the steps. The cooked rice is an intermediate result and there will be multiple intermediate results and these can be considered as the multiple DataFrames that are part of the lineage in generating the final DataFrame. Unless I wanted Egg fried rice I would not follow all these steps one by one:
Cook the rice
Break the eggs
Fry the rice and eggs with other ingredients.
If I wanted only rice it would be efficient to only cook the rice and the other steps can be omitted.So the same concepts apply to dataframe, if I only wanted the result of df1 it seems wasteful to even have df2.So just so that there is no unnecessary computation Spark decides to only register lineage as we declare transformations and compute results whenever called upon. The intermediate and final results that are computed are not persisted unless specified explicitly. If I ask Spark to compute df1, it will compute based on the lineage and will not remember the result. So the next time I call for results of df1, Spark again computes the results from reading the file in the above case. Intermediate result of df is not retained as well.
Since this is a behavior everytime we call for the results, it might not be suitable for every workload. In cases where one big common dataframe is involved in multiple operations, it would be wise to compute once and share whenever needed. Spark does provide support for caching results, which we will cover in another article. The tracking of lineage adds fault tolerant characteristics to all the APIs. Since Spark remembers how exactly to generate data, it can do so even in cases of any data related failures where the data that is cached is lost.
Actions:
The operations which elicit data computation are called actions. Unless one of these operations are called, Spark will not do any computation. A most common action operation in Spark is show() which will display the data after the completion of elicited computation.
Obviously there are multiple actions and transformations, some of them can be found in below table:
Conclusion:
This article should have given you the idea about the two different operations in Spark and the Lazy Evaluation, which is one of the main characteristics of Spark. If you have any suggestions or questions please post it in the comment box. This article, very much like every article in this blog, will be updated based on comments and as I find better ways of explaining things. So kindly bookmark this page and checkout whenever you need some reference.
Happy Learning! 😀
Comments
Post a Comment