Every row in a Dataframe is of type Row and this object comes with many methods with which we can interact with the data that it consists of. In this article I will dive deeper into the Row object
Row:
The objects of Row class can hold multiple values that correspond to columns. We can create Row objects separately or access Row objects from the existing dataframe. The Row class can be imported as follows:
from pyspark.sql import Row
There are several methods that can help retrieve row objects from the dataframe. Some of them are listed below:
df.collect() : This method returns a list of all rows that are present in the dataframe. The result is returned to the driver, so we should be careful while running this method as the driver might not have sufficient memory to hold all the Row objects.
df.take(num) : This method returns a list of a specific number of records, specified by the argument num that we are allowed to pass. The results are returned to the driver, so we should be mindful about the number which we pass as an argument.
df.first() : This method returns only the first row of the dataframe.
df.head(num) : This method returns a list of first n, specified by the argument num(not a mandatory argument, defaults to 1), rows. As the results are returned to the driver, the precautions mentioned above apply in this case as well.
df.tail(num) : This method returns a list of last n, specified by the argument num(not a mandatory argument, defaults to 1), rows. As the results are returned to the driver, the precautions mentioned above apply in this case as well.
As a first example, I am using df.first() to return only the first row. The returned object looks like
The printed value is the string representation of the Row object. The Row object offers different attributes and methods as mentioned earlier.
The attributes that are offered have the same name as the fields and indeed consist of the value for the respective field. In the above case, the Row object returned will have nine attributes: Name,Section,Gender,Total,English,Maths,Physics, Chemistry, Biology. We can access these attributes in three ways. The first way would be to access them as you would access any class attribute. Using the object, immediately followed by a dot and the name of the attribute:
row_obj = df.first()
print(row_obj.Name)
O/P: Raj
The above print statement would print the value of the field Name for the first Row. Another way to access attributes is to index with an attribute.
print(row_obj[‘Name’])
O/P: Raj
The final method to access the attributes is to index the object with numbers, treating the object as a non-key-value collection. The row object is zero-indexed, meaning the first field Name gets the index 0.
print(row_obj[0])
O/P: Raj
The Row object is provided with three methods to interact and format the data. The first method is the count(). This method is exactly like the count method provided in most Python collections. We are allowed to pass an argument which will be the value that is searched in the row and the result will be the number of occurrences of that particular value. So for example if I wanted to check in how many subjects did Raj score 20, I can do the following:
print(row_obj.count(20))
O/P: 4
As you can verify for yourself from figure 1 that Raj scored 20 marks four times and the result of the method reflects the same.
The second method provided is asDict(). This method formats the field names and its values as a Python dictionary. In the following example, the basic usage of asDict method is depicted with the corresponding output:
print(row_obj.asDict())
O/P: {'Name': 'Raj', 'Section': 'A', 'Gender': 'B', 'Total': 95, 'English': 15, 'Maths': 20, 'Physics': 20, 'Chemistry': 20, 'Biology': 20}
I mentioned that the above example is basic because there is an argument that the asDict function accepts, which is recursive and the accepted values as boolean True or False. This option becomes especially handy when we are dealing with StructType, or in simple words nested fields. Let’s take an example of Nested fields:
data_tmp =[('Jenny',('Jack','Julie'))]
schema_tmp ='Name STRING, Parents STRUCT<Father:STRING,Mother:STRING>'
df_tmp =spark.createDataFrame(data_tmp,schema_tmp)
df_tmp.show()
o/p:

I have created a temporary dataframe with two fields and two nested fields. The name field holds the Name of the student and Parent field holds both of the nested fields. The nested fields hold the names of both parents(Father and Mother). Now if I try the first() method on this data frame, the one and only row is returned and this is how it looks when displayed.
tmp_row = df_tmp.first()
print(tmp_row)
o/p:
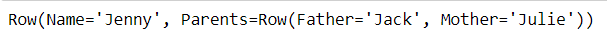
As you can see the value of Parents field is a nested Row object which contains the nested fields. When I try call the asDict() on the tmp_row object, I get something like the following:
tmp_row.asDict()
o/p:
The nested row and its attributes are not formatted as a dictionary. Because by default the asDict method does not format the nested rows to equivalent dict objects. To do that, we can use the aforementioned recursive argument like the following:
tmp_row.asDict(recursive=True)
o/p:
The final method provided in the Row object is the index() method. This method is identical to the index() method provided in lists, string or tuple objects. The index method allows us to search for a value’s appearance in the Row object. If the value is found in the Row object, the index position of first appearance is returned.
row_obj.index(20)
o/p:
5
The output is 5, as the first occurrence of 20 is in the sixth field and since Row objects are 0-indexed the resulting index is 5.
Creating Row objects:
This section elaborates on creating Row objects, unlike the previous section where I extensively covered how to access a row object from the dataframe, Row object’s methods and attributes. A Row object can be created in many ways because the class definition looks like:
Row(*args, **kwargs)
We have flexibility in creating row objectsThe following examples depict different ways in which we can create Row objects:
row = Row(Name='X',Section='A', Gender='B', Total=95,
English=89, Maths=99, Physics=88, Chemistry=77,
Biology=99)
data = {'Name': 'X','Section': 'A','Gender': 'B','Total': 95,
'English':89,'Maths': 99,'Physics': 88,'Chemistry': 77,
'Biology': 99}
row = Row(**data)
student = Row(‘Name’,'Section','Gender','Total',
'English','Maths','Physics',
'Chemistry',’Biology')
studentX = student('X','A','B',95,89,99,88,77,99)
student = Row(‘Name’,'Section','Gender','Total',
'English','Maths','Physics',
'Chemistry',’Biology')
data = ['X','A','B',95,89,99,88,77,99]
studentX = student(*data)
student_row = Row('X','A','B',95,89,99,88,77,99)
There are other methods which we can create Row objects as well, but these are the standard methods. The discussion of other methods will be appropriate when the createDataFrame method of Spark is elaborated, which will be covered in another article.
If you have worked with namedtuple in Python, you might discern the similarity. The first two methods are pretty self explanatory. But the last two methods work exactly like namedtuple. As a first step I create a Row class called student,with predefined field names. So any objects created with the student, will return a Row object. The values passed when calling the student will be taken as values for each field which were defined during the definition of student. This is depicted in the last two examples. This method becomes very handy when we have to create many row objects. Because we can define the field names once and when we need to create Row objects, passing only the values is sufficient. The final method shown is similar to the first step of the third or fourth method. The only difference is that instead of passing in the field names, I have passed the values as arguments. The fifth method creates a row with unnamed fields, fields do not have any name. Which is not the same result produced as in the case of the first four methods. We cannot use both positional and keyword arguments when creating a Row object, the below example depicts that:

Membership checks, Equality checks and other operations:
We are allowed to do membership check operations in a Row object. We can only check membership of fields within a Row object, checking whether a field is present in a Row. We can use the Python’s in keyword to perform a membership check. Example:
row = Row(Name='X',Section='A', Gender='B',
Total=95, English=89, Maths=99,
Physics=88, Chemistry=77, Biology=99)
print('Name' in row,'Chemistry' in row,'Psychology' in row)
print('Checking for values: ','X' in row)
O/p:
As the output indicates, only the column's membership can be checked.
The next we can perform with Row objects is equality checks. When we check whether two row objects are equal, the respective values, not field names, in the two row objects are checked for equality.
row1 = Row(Name='X',Section='A', Gender='B',
Total=95, English=89, Maths=99,
Physics=88, Chemistry=77, Biology=99)
row2 = Row(N='X',S='A', G='B', T=95, E=89, M=99, P=88, C=77, B=99)
row3 = Row('X','A', 'B', 95, 89, 99, 88, 77, 99)
row4 = Row(Name='Y',Section='A', Gender='B',
Total=95, English=89, Maths=99,
Physics=88, Chemistry=77, Biology=99)
print(row1 == row2,row1 == row3,row2==row3, row4 == row3)
O/p:
Creating Row objects will not be a frequent task in Spark, because big data comes in the form of files and data sources. Creating row objects is usually followed by creating a dataframe from a collection of rows. So knowing about the creation and working with rows will be helpful in small scale applications or POCs.
Conclusion:
I hope the extensive coverage of the rows in spark was helpful. If you have any suggestions or questions please post it in the comment box. This article, very much like every article in this blog, will be updated based on comments and as I find better ways of explaining things. So kindly bookmark this page and checkout whenever you need some reference.
Comments
Post a Comment